엉망진창과 전능함 사이 어딘가
AI는 몹시 똑똑한 동시에 멍청한 것 같습니다


우리 인간은, 다른 지능을 가진 생명체들과 마찬가지로, 정보를 적극적으로 찾아 헤맨다. 수동적으로 다음 토큰을 예측하는 것이 아니라.
—멜라니 미첼, <울퉁불퉁한 지능 – 거대 언어 모델 한 가운데 위험한 미지의 요소들>
엉망진창과 전능함 사이 어딘가
by 🥨채원
바야흐로 AI 시대입니다. 어딜 가나 AI라는 키워드에서 벗어나기 어렵습니다. 도대체 AI가 무엇인지, AI가 할 수 있는 것과 할 수 없는 것이 무엇인지 알쏭달쏭한 채로, 이 변화에 적응하지 못하면 곧 도태될 것 같은 두려움에 시달립니다. AI란 키워드가 이렇게 만연하면서도 AI가 무엇인지 명확하게 설명하기 어려운 이유는 여러 가지가 있지만, 그중 하나는 종종 전능해 보이기도 하는 AI가 때로는 무척이나 엉망진창인 결과를 내놓기 때문입니다.
한 편에서 수학 올림피아드 대회를 우승하고, 변호사 시험을 통과한다는 AI가 간단한 수학 문제를 틀리고, 터무니없는 거짓말을 그럴듯하게 뻔뻔히 내놓기도 합니다. 이런 격차는 어디서 오는 걸까요? AI가 진짜 존재하는 곳은 엉망진창과 전능함 사이 어디일까요?

실리콘 밸리에서 끊임없이 내놓는 막연한 낙관에 기댈 수도 없지만 동시에 이대로 무기력하게 닥쳐오는 변화를 받아들이는 것도 불편합니다. 눈을 가린 채 달리는 경주마처럼 이대로 질주하다가는 19세기의 철도왕들이, 20세기의 닷컴버블이 그랬던 것처럼 반드시 어딘가 무너질 것 같습니다. ‘번영과 파멸을 동시에 볼 수 있는’ 오늘날 개인인 내가 길을 잃지 않고서 살아가는 데 무엇을 알아야 하는지 막막하게 느껴지기도 하고요.
AI에 모두가 이야기하고 있지만, 모두의 목소리가 같은 무게를 갖고 전달되는 것은 아닙니다. AI 담론은 특히 극소수의 기업들, 특히 실리콘밸리에 있는 몇몇 소수 테크 기업들에 의해 과점 되었다고 해도 과언이 아닙니다. 그러므로, 이들의 목소리 외의 다른, 더 작고 다양한 담론들에도 귀 기울이는 것이 중요합니다. 거대 담론에서 강조하지 않는, AI를 둘러싼 다층적이고 미묘한 면면들을 살펴보고 이해하려는 노력이 절실합니다.
처음에 든 예시로 다시 돌아가 보겠습니다. 매우 어려운 일을 척척 해내는 것 같은 AI가 명백하고 어처구니없는 거짓말을 뻔뻔하게 내놓는 이유는 뭘까요? 이러한 현상에는 다양한 원인과 설명이 있지만, 제가 최근 주목하고 있는 설명은 대개 거대 언어모델(LLM)로 대표되는 AI 모델의 ‘지능’의 지면이 울퉁불퉁하다는 (’jagged intelligence’) 주장입니다. AI를 평가하는 데 있어 ‘지능’이라는 단어를 사용하는 것이 적절한가 하는 논란도 있지만, 이 글에서는 일단 널리 사용되는 용어라는 측면에서 사용하도록 하겠습니다.
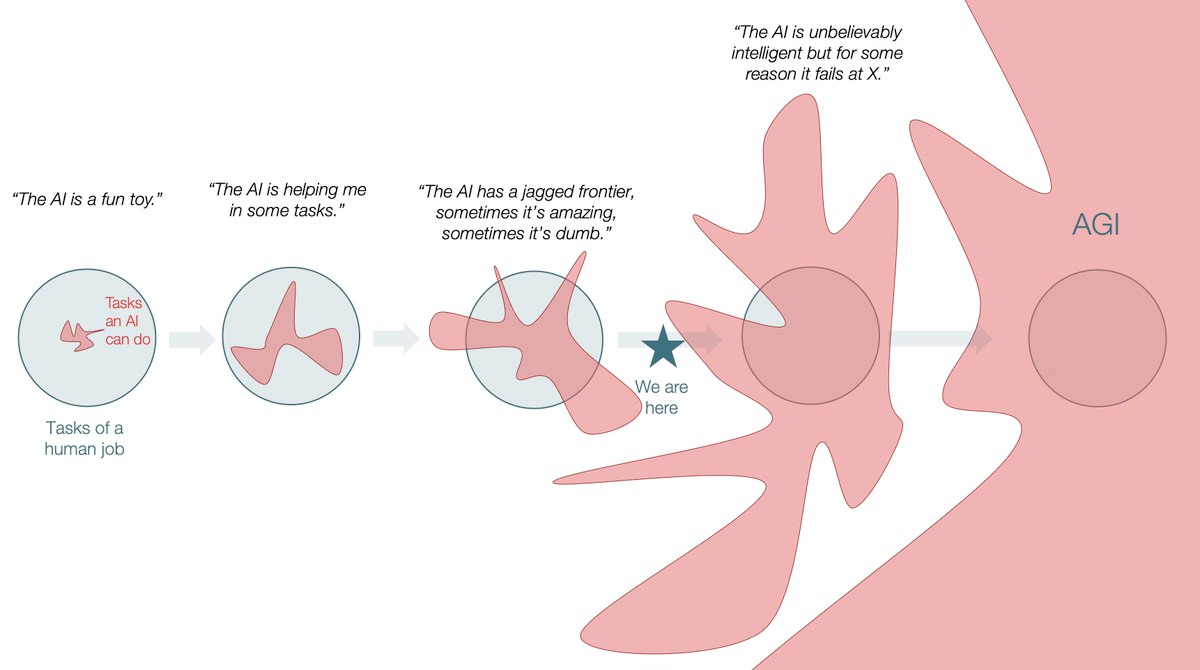
인간의 경우, 어떤 분야에서 훌륭한 능력을 보이는 경우, 그와 비슷한 분야에서도 마찬가지로 훌륭한 능력을 보일 것이라고 예상할 수 있습니다. 그러나 AI의 경우 비슷한 결과를 상정하기 어렵습니다. 왜냐하면 많은 데이터를 기반으로 학습한 현재의 AI는, 무엇을 학습했느냐에 따라 수행 능력이 현저하게 차이 나기 때문입니다.
2026년 여름을 기준으로 오픈AI에서 최근 출시한 GPT-5.5 모델을 예시로 살펴보겠습니다. 오픈AI는 GPT-5.5를 ‘진짜 업무를 위한 새로운 차원의 지능’이라고 소개하며 다양한 사용 후기를 공유했는데요, 그중 한 제약회사 CEO는 ‘방대한 생화학 데이터를 분석하여 약물 반응을 예측하고, 가장 까다로운 신약 개발 평가에서 모델이 놀라운 정확도 향상’하였고, 따라서 ‘OpenAI가 지금처럼 혁신적인 성과를 계속 낸다면, 올해 말에는 신약 개발의 판도가 완전히 바뀔 것’이라고 예측하였습니다. 생화학 데이터를 분석하고, 신약을 개발하는 것은 분명 매우 까다로운 일일 것입니다. 그렇다면 다른 복잡한 일들도 그만큼 잘할까요? 그렇지 않습니다. 놀랍게도 많은 최신 AI 모델들이 시계를 읽지 못한다는 사실을 알고 계셨나요? GPT-5.5도 예외가 아닙니다. ClockBench라는 벤치마크에 따르면 GPT-5.5는 시계 이미지의 절반밖에 읽지 못합니다.
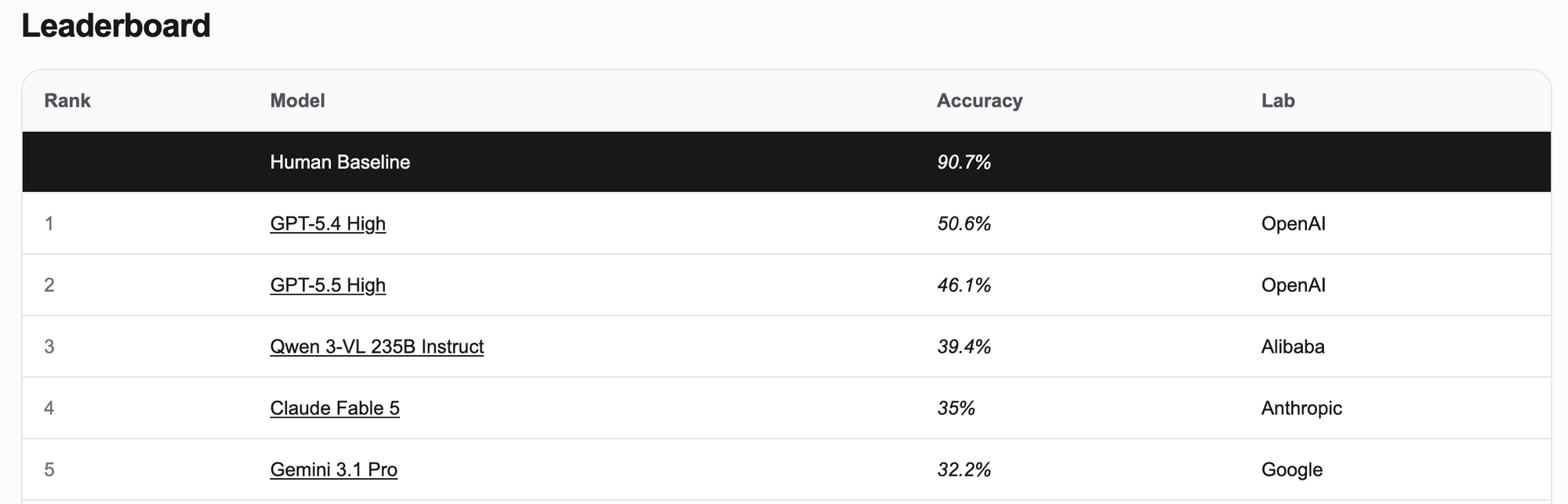
비슷한 예시로는 도형 읽기 문제가 있습니다. 2025년 8월 발표된 논문에서 연구진은 (일명 AI의 대부로 불리는 얀 르쿤이 저자 중 한 명으로 포함되어 있습니다) 현재의 시각 언어 모델들이 도형 변의 개수를 세는 단순한 과제에 취약하다는 것을 발견했습니다. 오각형, 칠각형 같은 단순한 형태의 도형뿐만 아니라, 여러 도형을 합친 응용 형태의 도형은, 대부분의 현존 기술이 ‘해당 이미지의 형태가 몇 개의 변을 갖고 있느냐’라는 질문의 정답을 맞히지 못했습니다. 특히 칠각형의 경우 대부분의 모델이 전혀 정답을 맞히지 못했습니다. 해당 데이터 세트를 GPT-5.5에 시험한 결과는 찾지 못했으나, 시계 읽기 문제와 비슷할 것으로 예상됩니다.
너무나도 똑똑해 보이는 AI 기술들이 왜 이렇게 쉬운 문제를 틀리는 걸까요? 기본적으로 언어 모델은 질문에 대한 정답을 논리적으로 맞추는 모델이 아니라, 주어진 입력값을 기준으로 그다음에 가장 나올 것 같은 값을 출력하는 확률 기반 모델이기 때문입니다. 따라서 특이한 형태의 도형 등 학습할 때 보지 못했던 데이터들이나, 시계처럼 이미지 자체는 대동소이하지만 아주 미묘한 차이가 전혀 다른 의미로 이어지는 경우 고전하는 것이죠. 이렇게 문제의 종류마다 극단적으로 달라지는 AI의 행동은, 이 알쏭달쏭한 기술을 이해하기 더욱 어렵게 만듭니다.

이러한 일련의 예시가 시사하는 바는 분명합니다. 사람의 능력을 이해하고 평가하는 방식으로는 AI의 능력을 이해하거나 평가할 수 없다는 것입니다. 사실 이는 인간과 동물을 비교할 때를 생각해 보면 자연스럽게 이해됩니다. 강아지들의 운동 능력을 평가하는 어질리티 평가를 사람이 잘 수행하는지 평가하지 않는 것이 무의미한 것처럼, 사람을 대상으로 만든 시험들(예컨대 변호사 시험)을 AI가 잘 시행한다고 해서 AI가 변호사가 될 수 있다는 것을 의미하지는 않습니다. 그렇다면 우리는 어떻게 해야 AI를 정확하게 이해할 수 있을까요? 아직은 정답이 없는 어려운 문제지만, 일단 우리가 할 수 있는 것은 명료하고 단순한 선전 (예컨대 ‘클로드가 모든 화이트칼라 노동을 대체할 것이다’)를 경계하고, AI를 둘러싼 복잡한 현상을, 있는 그대로 바라보는 것입니다. 그리고 그 이면의 다양한 맥락들을 천천히 살펴보고, 또 비슷한 고민을 하는 사람들과 이야기 나누다 보면 무언가 깨닫게 되지 않을까요?
#feedback
오늘 이야기 어떠셨나요?
여러분의 유머와 용기, 따뜻함이 담긴 생각을 자유롭게 남겨주세요.
남겨주신 의견은 추려내어 다음 AI 윤리 레터에서 함께 나눕니다.