불완전한 AI 서비스의 시대
불완전한 AI 서비스의 시대. 챗GPT o1 프리뷰. 소다 및 스노우 외설스러운 사진 합성 이슈. 네이버의 소버린 AI.

누군가의 취미가 누군가의 산업이 되고, 처음에는 어설프게 만든 물건이 잘 갖춰진 생산 라인에서 제품으로 탄생하고, 공짜로 접근 가능했던 채널이 단일한 기업 또는 기업 카르텔에 의해 엄격히 통제되는 채널이 된다.
—프랭클린 포어, 이승연·박상현 옮김, <생각을 빼앗긴 세계> (반비, 2019), p.237
AI 윤리 뉴스 브리프
2024년 9월 4째 주
by 🧙♂️텍스
목차
1. 오픈AI의 챗GPT o1 프리뷰 공개
2. AI 사진 앱의 외설스러운 사진 합성
3. 소버린 AI와 파운데이션 모델, 그리고 서비스
1. 오픈AI의 챗GPT o1 프리뷰 공개
2. AI 사진 앱의 외설스러운 사진 합성
3. 소버린 AI와 파운데이션 모델, 그리고 서비스
1. 오픈AI의 챗GPT o1 프리뷰 공개
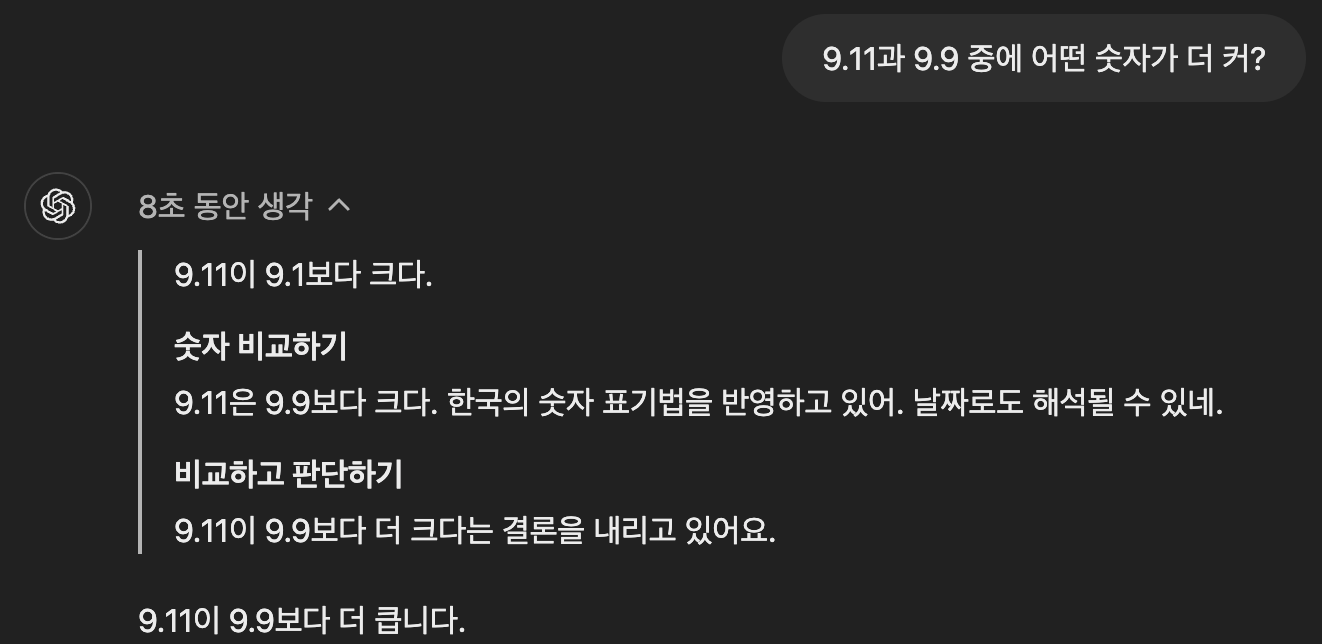
- 2024년 9월 12일, 오픈AI는 새로운 모델인 챗GPT o1을 프리뷰로 공개했습니다. 이 모델은 챗GPT에서 하나의 질문에 대해 복수의 답변과 추론 과정을 생성하도록 학습되었으며, 이 중에서 최선의 답변을 선택하는 능력을 강화했습니다. 추론 과정에서 복수의 응답을 선별하는 단계를 추가하고, 이를 위해 더 많은 시간과 계산 자원을 할당한 점에서 기존의 모델과 차별화됩니다. 데이터와 모델의 규모가 성능을 담보한다는 신경망 스케일 법칙(neural scaling law)이 학습 과정에만 적용되었다면, 이제는 이 법칙이 추론 과정에 걸리는 시간에도 확장되어 적용되고 있습니다.
- 자연스럽게, 여러 번의 질의 과정을 반복하면 오류가 발생할 확률은 기계적으로 줄어듭니다. 오픈AI의 챗GPT o1 프리뷰 공개 전, 오픈AI가 새 모델에 대해 최대 월 $2000의 구독제를 고려 중이라는 뉴스가 있었습니다. 현재 챗GPT 구독료가 월 $20임을 감안하면, 가장 비싼 모델은 추론 과정에 꽤 많은 자원을 할당하리라고 추측해 볼 수 있습니다. 이 정도의 계산 자원을 할당하면 AGI를 만들기에 충분한 성능을 제공하고 AI 정렬(Alignment) 또한 잘 이루어진다고 오픈AI가 자신하는지 궁금해집니다.
- 다만 아쉬운 점은 어떤 응답과 추론 과정을 좋은 것으로 간주할지에 대한 기준이 공개되지 않았다는 사실입니다. 최근 공개된 AI 안정성을 위한 강화학습 기법인 Rule-based Rewards에서 일부 기준을 다루고 있지만 그 외의 방법론에 대해서는 알려진 바가 없습니다. 심지어 오픈AI는 새로운 모델의 작동을 분석하는 유저들에게 경고하는 등 서비스용 AI 모델을 더욱더 불투명하게 만들고 있습니다. 오픈AI는 새로운 모델이 기존 모델 대비 비약적인 성능 향상을 보여준다고 주장하고 있습니다. 하지만, 기초적인 산수인 9.11과 9.9의 크기를 혼동하고, 추론 기준이 불투명한 모델에 대한 신뢰는 고민해 봐야 할 문제일 것으로 보입니다.
🦜
더 읽어보기
- OpenAI Threatens to Ban Users Who Probe Its ‘Strawberry’ AI Models (Wired, 2024-09-17)
- OpenAI Threatens to Ban Users Who Probe Its ‘Strawberry’ AI Models (Wired, 2024-09-17)
2. AI 사진 앱의 외설스러운 사진 합성
- 최근 기사에서는 네이버 자회사 스노우의 소다(SODA)와 스노우(SNOW) 사진 앱에서 제공하는 유료 AI 이미지 서비스에서 사용자가 의도하지 않은 외설스러운 사진이 합성되는 문제가 제기되었습니다. 스노우 측은 네거티브 프롬프트(negative prompt)를 통해 이러한 문제를 필터링하려 했으나, 이 기능이 완벽하게 작동하지 않았음을 인정하며, 앞으로 이를 더욱 고도화할 계획을 밝혔습니다.
- 그러나 원치 않는 결과에 대한 설명은 담은 네거티브 프롬프트의 개선은 필요하지만 근본적인 해결책은 아닙니다. 지난 번 AI 윤리 레터에서 공개 데이터셋인 LAION-5B가 여러 포르노 사이트로부터 데이터를 가져와 아동 성 착취물까지 포함하고 있다는 사실을 지적한 바 있습니다. 학습 데이터에 외설 이미지가 없다면 이러한 문제가 발생할 가능성은 매우 낮아지기 때문에, 이미지 생성 파운데이션 모델부터 철저히 검증되어야 합니다.
- 하지만, 파운데이션 모델의 검증 및 재학습은 큰 비용을 수반하기 때문에 개별 기업들은 네거티브 프롬프트와 같은 임시방편적 해결책을 선택하는 유혹을 받습니다. 따라서 실질적인 문제 해결을 위해서는 모든 기업에 동등하게 적용될 수 있는 정책이 필요합니다. 예를 들어, 문제를 야기한 파운데이션 모델의 폐기를 강제하는 등의 조치가 고려될 수 있습니다. 오픈소스 파운데이션 모델을 사용했다는 것이 면죄부가 될 수는 없기 때문입니다.
🦜
더 읽어보기
- 사진 내리기 말고 할 수 있는 일: AI 기업에 요구하기 (2024-09-04)
- 사진 내리기 말고 할 수 있는 일: AI 기업에 요구하기 (2024-09-04)
3. 소버린 AI와 파운데이션 모델, 그리고 서비스
- 지디넷이 2024년 9월 16일에 보도한 네이버 하정우 퓨처AI센터장 인터뷰는 미국 시장 외의 기업이 AI에 어떻게 대응하고 있는지를 잘 보여주는 기사입니다. 최근 AI 관련 다양한 주제를 기업의 관점에서 다루고 있어 흥미롭게 읽을 수 있었습니다.
- 하 센터장은 자본 규모에서 큰 차이를 보이는 글로벌 빅테크와의 직접적인 기술 경쟁을 피하고, AI를 활용한 킬러 애플리케이션 서비스 발굴에 집중해야 한다고 주장합니다. 또한, 국내를 넘어 중동이나 아세안 지역에서 파트너 국가를 찾아 소버린 AI 개발을 추진하고, 이를 통해 AI를 수출해야 한다고 강조합니다. 그는 소버린 AI가 단순히 네이버의 어젠다가 아닌 대한민국의 성장 어젠다임을 강조하며, 개별 기업이 글로벌 빅테크와 경쟁하는 것은 어렵기 때문에 정부 주도의 적극적인 지원이 필요하다고 덧붙였습니다.
- 그러나 여전히 AI의 킬러 애플리케이션이 발굴되지 않은 상황에서 소버린 AI를 개발하는 것이 어떤 의미를 가지는지 의문이 듭니다. 소버린 AI라는 추상적인 개념보다는 AI 시대의 전자정부와 같은 구체적인 서비스에 집중하는 것이 더 효과적이지 않을까 생각됩니다. 또한, 국가 차원에서 GPU 컴퓨팅 센터를 구축하는 데 들어가는 막대한 투자에 비해 한국이 실질적으로 얻을 수 있는 이익이 얼마나 될지 고민하게 됩니다. 빅테크의 파운데이션 모델이 한국어 성능이 떨어지는 것은 품질 높은 한국어 데이터의 규모가 작은 것이 한 이유일 것이기에, 한국어 공개 데이터만 잘 구축해도 좋은 성능을 기대할 수 있습니다. 그렇다면 한국 회사들이 파운데이션 모델을 개발해야 할 이유는 무엇일까요?
🦜
#feedback
오늘 이야기 어떠셨나요?
여러분의 유머와 용기, 따뜻함이 담긴 생각을 자유롭게 남겨주세요.
남겨주신 의견은 추려내어 다음 AI 윤리 레터에서 함께 나눕니다.



