2025년의 AI 윤리
2025년 새로운 AI 기술을 맞이하기 위한 태도

"여러분 중 자신이 한 일의 윤리적 의미에 대해 생각해본 사람은 몇 명인가요?"
—윤송이 외 지음, <가장 인간적인 미래>
1. 2025년 AI윤리 담당자의 다짐
2. 다시 전면에 등장한 AGI
2025년 AI윤리 담당자의 다짐
by. 🎶소소
인간을 닮은 지능을 목표했던 AI 기술이 필연적으로 우리 삶과 사회 곳곳에 스며들고 있습니다. 2025년, 우리는 또 얼마나 새로운 기술을 맞이하게 될까요? 사람의 능력을 뛰어넘은 AGI가 등장했다는 소식이 하루가 멀다고 들려오는데, 우리 사회는 어떤 준비를 해야 할까요? 인간이 저질러 온 실수를 AI로 반복하지 않도록, 나아가 더 심각한 결과를 만나지 않으려면 올해는 무엇을 더 해야 할지 고민이 많은 AI 윤리 담당자입니다.
AI 기업에서 AI 윤리를 이야기하다 보면 종종 “뜬구름 잡는 소리 같다.”는 반응을 마주하게 됩니다. 문제의식은 공감하지만, 당장의 기술 성능을 높이고 사업 성과를 만드는 일에 어떻게 적용해야 할지 모르겠다는 말과 함께요. 이러한 반응은 어쩌면 당연할지도 모릅니다. 마치 “대한민국은 민주공화국이다.”라는 헌법 제1조 1항이 평화로운 일상에서는 추상적이고 당연한 선언으로만 들리다가, 국민의 주권이 위협받는 순간에야 비로소 그 의미와 가치가 다가오는 것처럼 말입니다. 그러나 AI 기술이 만드는 예기치 못한 문제들이 발생하기를 기다릴 수만은 없습니다.
많은 AI 기업이 혁신적인 AI 기술로 세상을 더 나은 곳으로 만들겠다고 말합니다. 작정하고 AI를 나쁜 일에 쓰겠다는 악의적인 인간은 극소수일 것입니다. 그러나 기술 개발에 몰두하다 보면 목표 성능 이상을 생각하기 어렵습니다. 전 세계적인 기술 경쟁 속에 시간도 부족합니다. 그리고 문제는 우리가 기술에 집중하는 동안 다음으로 미뤄둔 영역에서 터집니다. 기업에서 AI 윤리 담당자의 역할은 기술의 성능 이상의 사회적 영향력을 생각할 시간과 도구를 마련해주는 일이라고 생각합니다. 기술이 실제 어떻게 사용될지, 사회에 어떤 영향을 미칠지 가장 깊게 고민하고 해결의 실마리를 찾을 수 있는 사람은 직접 기술을 만들고 활용하는 이들이니까요.

올해는 AI 윤리가 '뜬구름 잡는 소리'로 들리지 않게 하기 위해 무엇을 해야 할지 고민이 깊어집니다. 그동안은 제도나 정책이 윤리적 원칙을 실행 가능한 형태로 만들 수 있다고 생각했습니다. 그래서 이론적으로 문제없고 당위성 있는 정책을 만들기 위해 노력해 왔습니다. 그러나 정책이나 제도만으로 모든 문제를 해결할 수는 없었습니다. AI 연구개발 과정에 참여하는 모든 사람이 AI 윤리를 조금 더 내 일처럼 고민하게 만들 수 있을까요? AI 윤리를 고민하는 것이 곧 좋은 AI를 만드는 것임을 모든 구성원이 스스로 깨닫고 이야기할 수 있는 방법을 찾아보고 싶습니다.
의사가 히포크라테스 선서로 생명을 지키겠다는 맹세를 하고, 법률가가 정의 실현을 위해 노력하듯이, AI 전문가도 당연하게 기술 윤리를 마음에 품게 되기를 기대하며, 그때까지 한 걸음씩 나아가보려 합니다.
다시 전면에 등장한 AGI
by. 🧙♂️텍스
작년 12월 오픈AI는 12 Days of OpenAI로 연달아 새로운 내용을 발표하였고, 마지막 날에 새로운 추론 모델 o3를 발표했습니다. 특히, o3가 ARC-AGI (Abstraction Reasoning Corpus for Artificial General Intelligence)라는 벤치마크에서 사람 성능을 넘었다고 언급하였습니다. 이 사실을 다룬 많은 기사는 AGI 달성이 이루어진 것처럼 언급했습니다만 조금만 살펴봐도 이 내용이 얼마나 과장인지 확인할 수 있습니다.
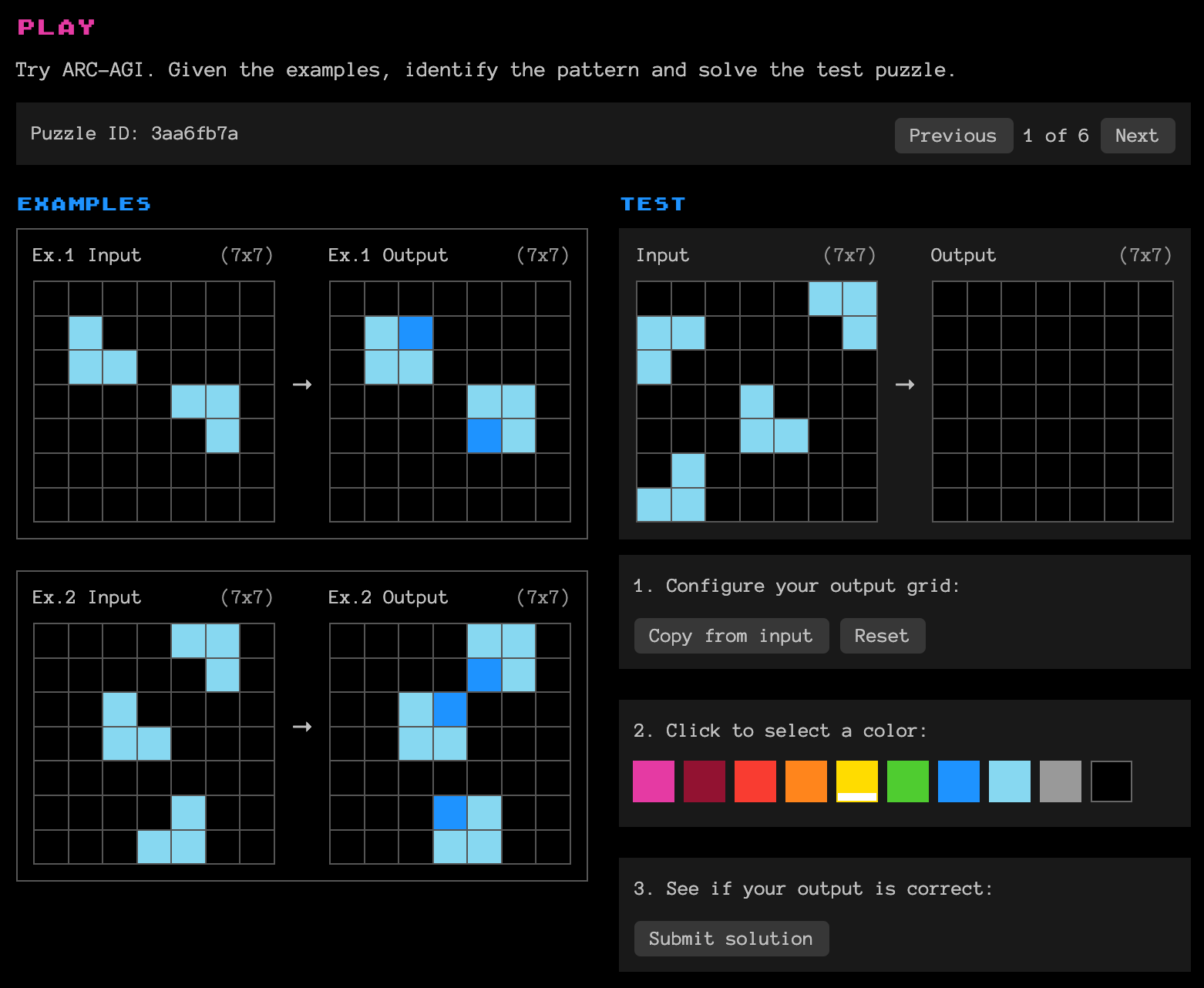
2019년 프랑수와 샬레 (François Chollet)는 기존의 AI 벤치마크가 특정 작업만을 다루는 좁은 범위의 지능을 평가한다고 한계를 이야기했습니다. ARC-AGI 벤치마크는 새로운 문제에 맞닥뜨렸을 때 이를 해결하는 지능을 평가하기 위해 도입되었습니다. 위의 예시와 같이, ARC-AGI는 소수의 예시에서 관계성을 추론해 내는 문제로 보통 사람에게는 그렇게 어려운 문제는 아닙니다. 하지만 수많은 데이터의 규칙성으로 추론을 하는 기계학습 알고리즘에는 거의 불가능한 문제였습니다. 거대언어모델의 경우 인터넷상의 데이터를 암기했기 때문에 수많은 지식을 뱉어내는 데는 능합니다. 하지만, 적은 수의 데이터에서 유의미한 패턴을 추론하는 데는 어려움을 겪습니다. ARC-AGI가 등장한 5년 동안 수많은 시도가 있었지만, GPT-4o를 포함하여 인간의 성능에는 턱없는 수치를 보여주었습니다. 그리고 작년 연말 오픈AI는 이 문제에서 사람 수준에 도달했다고 이야기한 것입니다.
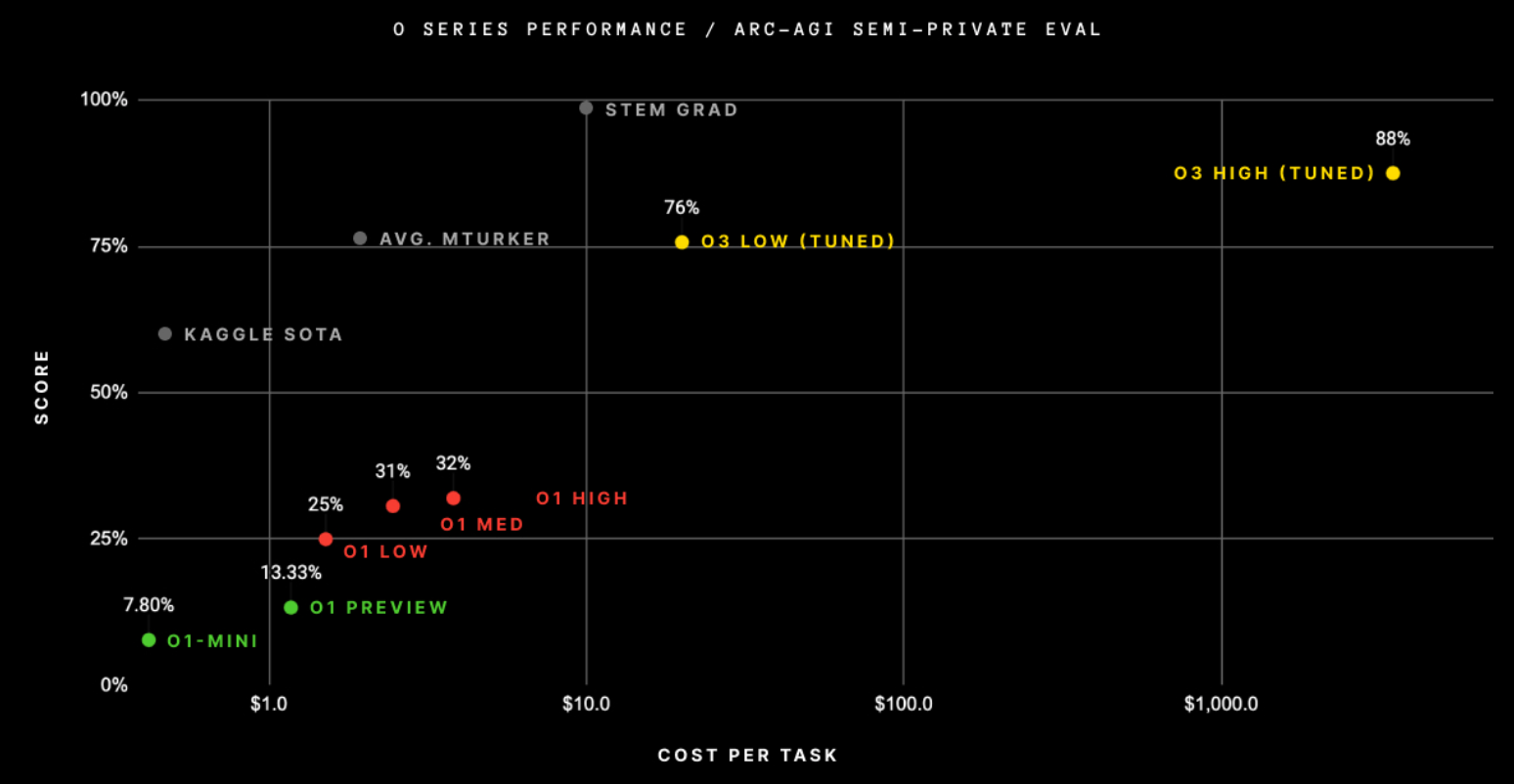
ARC-AGI 블로그에서 공개한 오픈AI o3 성능 그래프는 현실을 명확히 보여줍니다. 적은 계산량(?)을 사용한 O3 LOW는 평균적인 아마존 메커니컬 터크 상 데이터 라벨러(AVG. MTURKER)와 비슷한 성능을 보여주었습니다. 그리고 O3 HIGH 모델은 데이터 라벨러는 넘었지만 이공계열 대학원생(STEM GRAD)에는 한참 못 미치는 성능을 달성했습니다. 이 부분이 사람의 성능을 넘었다고 주장하는 부분인데, ARC-AGI 블로그 포스팅에서도 벤치마크 성능이 AGI의 도래와 같은 것이 아니라고 언급하고 있습니다. 협소한 합성 데이터 기반 벤치마크 하나에서 데이터 라벨러의 성능을 넘었다는 사실이 근시일내 AGI의 도래를 말하는 근거로 인용되는 것에는 주의를 기울여야 할 것입니다.
또한, 그래프를 자세히 살펴보면 O3 LOW 추론 알고리즘이 데이터 라벨러보다 10배나 비싸다는 것을 알 수 있습니다. 그래프의 x축은 단위 작업에 대한 비용을 로그 스케일로 나타내었습니다. O3 HIGH 모델은 O3 LOW보다 172배 계산량을 더 사용했다고 합니다. 그래프만 보았을 때 현재 o3와 같은 추론 알고리즘이 비용을 더 투자한다고 해서 이공계 대학원생 수준까지 도달할 수 있을지는 의문이 듭니다. 추론할 때 계산량을 투입하여 성능을 끌어올릴 수 있다는 추론 시간 신경망 스케일링 법칙의 한계가 벌써 드러난 것이 아닐까 추정해 봅니다.
#feedback
오늘 이야기 어떠셨나요?
여러분의 유머와 용기, 따뜻함이 담긴 생각을 자유롭게 남겨주세요.
남겨주신 의견은 추려내어 다음 AI 윤리 레터에서 함께 나눕니다.



